results <- read_html("https://taskmaster.fandom.com/wiki/Series_11") |>
html_element(".tmtable") |>
html_table() |>
mutate(episode = ifelse(startsWith(Task, "Episode"), Task, NA)) |>
fill(episode, .direction = "down") |>
filter(!startsWith(Task, "Episode"),
!(Task %in% c("Total", "Grand Total"))) |>
pivot_longer(cols = -c(Task, Description, episode),
names_to = "contestant",
values_to = "score") |>
mutate(series = 11)Regular Expressions II
Jo Hardin
2024-01-12
Lookaround
A lookaround specifies a place in the regular expression that will anchor the string you’d like to match.
- “x(?=y)” – positive lookahead (matches ‘x’ when it is followed by ‘y’)
- “x(?!y)” – negative lookahead (matches ‘x’ when it is not followed by ‘y’)
- “(?<=y)x” – positive lookbehind (matches ‘x’ when it is preceded by ‘y’)
- “(?<!y)x” – negative lookbehind (matches ‘x’ when it is not preceded by ‘y’)
Lookaround

Figure 1: Image credit: Stefan Judis https://www.stefanjudis.com/blog/a-regular-expression-lookahead-lookbehind-cheat-sheet/
Example - Taskmaster
Data scraped from the wiki site for the TV series, Taskmaster.
Figure 2: Taskmaster Wiki https://taskmaster.fandom.com/wiki/Series_11
Scraping and wrangling Taskmaster
Goal: to scrape the Taskmaster wiki into a dataframe including task, description, episode, episode name, air date, contestant, score, and series.1
Scraping and wrangling Taskmaster data - results
# A tibble: 10 × 6
Task Description episode contestant score series
<chr> <chr> <chr> <chr> <chr> <dbl>
1 1 Prize: Best thing you can carry, but on… Episod… Charlotte… 1 11
2 1 Prize: Best thing you can carry, but on… Episod… Jamali Ma… 2 11
3 1 Prize: Best thing you can carry, but on… Episod… Lee Mack 4 11
4 1 Prize: Best thing you can carry, but on… Episod… Mike Wozn… 5 11
5 1 Prize: Best thing you can carry, but on… Episod… Sarah Ken… 3 11
6 2 Do the most impressive thing under the … Episod… Charlotte… 2 11
# ℹ 4 more rowsmore succinct results
Task Description episode contestant score series
1 Prize: Best thing… Episode 1… Charlotte… 1 11
1 Prize: Best thing… Episode 1… Jamali Ma… 2 11
1 Prize: Best thing… Episode 1… Lee Mack 4 11
1 Prize: Best thing… Episode 1… Mike Wozn… 5 11
1 Prize: Best thing… Episode 1… Sarah Ken… 3 11
2 Do the most… Episode 1… Charlotte… 2 11
2 Do the most… Episode 1… Jamali Ma… 3[1] 11
2 Do the most… Episode 1… Lee Mack 3 11
2 Do the most… Episode 1… Mike Wozn… 5 11
2 Do the most… Episode 1… Sarah Ken… 4 11Currently, the episode column contains entries like
Cleaning the score column
How should the scores be stored? What is the cleaning task?
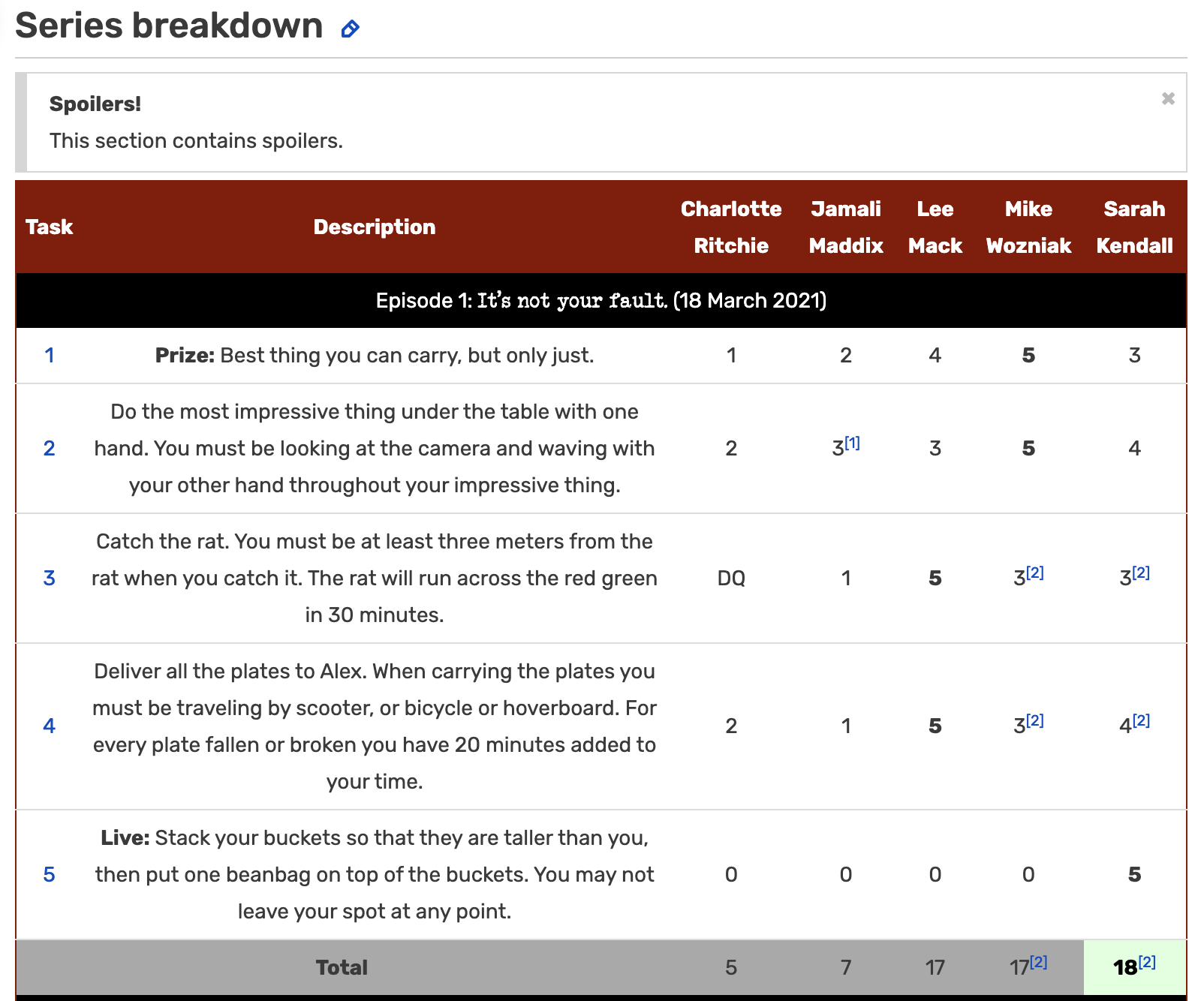
Figure 3: Taskmaster Wiki https://taskmaster.fandom.com/wiki/Series_11
Extracting numeric information
Suppose we have the following string:
And we want to extract just the number “3”:
Extracting numeric information
What if we don’t know which number to extract?
str_extract()
str_extract() is an R function in the stringr package which finds regular expressions in strings of text.
Matching multiple options
str_extract() returns the first match; str_extract_all() allows more than one match.
Matching groups of characters
What if I want to extract a number?
What will the result be for the following code?
Matching groups of characters
What if I want to extract a number?
What will the result be for the following code?
Matching groups of characters
What if I want to extract a number?
What will the result be for the following code?
The + symbol in a regular expression means “repeated one or more times”
Extracting from multiple strings
Extracting from multiple strings
What if we have multiple instances across multiple strings? We need to be careful working with lists (instead of vectors).
Extracting episode information
Currently, the episode column contains entries like:
How would I extract just the episode number?
Extracting episode information
Currently, the episode column contains entries like:
How would I extract just the episode number?
Extracting episode information
Currently, the episode column contains entries like:
How would I extract the episode name?
Goal: find a pattern to match: anything that starts with a :, ends with a .
Let’s break down that task into pieces.
Extracting episode information
How can we find the period at the end of the sentence? What does each of these lines of code return?
Extracting episode information - solution
[1] "Episode 2: The pie whisperer. (4 August 2015)"We use an escape character when we actually want to choose a period:
Extracting episode information
Goal: find a pattern to match: anything that starts with a :, ends with a .
Lookaround (again)
Figure 4: Image credit: Stefan Judis https://www.stefanjudis.com/blog/a-regular-expression-lookahead-lookbehind-cheat-sheet/
Lookbehinds
(?<=) is a positive lookbehind. It is used to identify expressions which are preceded by a particular expression.
[1] "The pie whisperer. (4 August 2015)"Lookaheads
(?=) is a positive lookahead. It is used to identify expressions which are followed by a particular expression.
[1] "Episode 2: The pie whisperer"Extracting episode information
Getting everything between the : and the .
Extracting air date
I want to extract just the air date. What pattern do I want to match?
Extracting air date
Wrangling the episode info
Currently:
# A tibble: 270 × 1
episode
<chr>
1 Episode 1: It's not your fault. (18 March 2021)
2 Episode 1: It's not your fault. (18 March 2021)
3 Episode 1: It's not your fault. (18 March 2021)
4 Episode 1: It's not your fault. (18 March 2021)
5 Episode 1: It's not your fault. (18 March 2021)
6 Episode 1: It's not your fault. (18 March 2021)
# ℹ 264 more rowsWrangling the episode info
One option:
results |>
select(episode) |>
mutate(episode_name = str_extract(episode, "(?<=: ).+(?=\\.)"),
air_date = str_extract(episode, "(?<=\\().+(?=\\))"),
episode = str_extract(episode, "\\d+"))# A tibble: 270 × 3
episode episode_name air_date
<chr> <chr> <chr>
1 1 It's not your fault 18 March 2021
2 1 It's not your fault 18 March 2021
3 1 It's not your fault 18 March 2021
4 1 It's not your fault 18 March 2021
5 1 It's not your fault 18 March 2021
6 1 It's not your fault 18 March 2021
# ℹ 264 more rowsWrangling the episode info
Another option:
# A tibble: 270 × 3
episode episode_name air_date
<chr> <chr> <chr>
1 1 It's not your fault 18 March 2021
2 1 It's not your fault 18 March 2021
3 1 It's not your fault 18 March 2021
4 1 It's not your fault 18 March 2021
5 1 It's not your fault 18 March 2021
6 1 It's not your fault 18 March 2021
# ℹ 264 more rowsRegular expressions and SQL
Back to the IMDb database…
| production_year | title |
|---|---|
| 2005 | "Dancing with the Stars" (I) |
| 2005 | "Dancing with the Stars" (II) |
| 2005 | "Dancing with the Stars" (III) |
| 2017 | "Girl Starter" (II) |
| 2001 | "Popstars" (I) |
| 2001 | "Popstars" (II) |
| 2002 | "Popstars" (I) |
| 2000 | "Popstars" (I) |
| 1959 | "Startime" (II) |
| 1959 | "Startime" (I) |
Course project
Don’t forget, next week, each person will be working on their own mini project!
- Using SQL queries and joins to wrangle complicated data tables.
- Writing regular expressions to parse observations.
- Creating a SQL database.
- email
jo.hardin@pomona.eduby Tuesday, Jan 16 with an idea of what you plan to do.- Question of interest that you hope to address.
- Holistic description of the dataset(s) (a few sentences).
- Description of the observational units and columns in each data table.
- Full reference for data citation.
- Link to the resources.